土木工程结构在长期服役过程中,由于各种因素影响,结构会发生一定程度的损伤和损伤累积。为了保证结构安全运营,许多大型重要结构安装了结构健康监测(SHM)系统[1-3],这些SHM系统产生的监测数据随着时间推移逐渐趋于海量化[4-6],每天的监测数据可能达到GB甚至更高级别。为了及时处理这些监测数据,一些学者开始尝试结合当下热门的云计算平台,采用并行分布式方法来处理、评价结构工作状态。
云计算是一种按需取用计算资源的模式,这种模式提供可配置的计算资源共享池,只需要进行少量的管理工作并与服务器进行,就可获得大量计算资源[6―7]。要确保云计算的运算效率,需要用到并行计算和分布式计算:并行计算[8]是与串行计算相对的一种计算方法,它是一种一次可执行多条指令的算法,它可以提高计算速度,解决大型而复杂的计算问题;分布式计算[9]是一种与集中式计算相对的一种计算方法,它将需要庞大计算能力才能解决的问题分解成许多小的部分,分配给多台计算机进行处理,节约计算时间,提高计算效率。目前,云计算方法已成功运用于金融、医疗、电网、地理信息等领域[10],近年部分学者尝试将云计算方法应用到结构健康监测之中[11―14]。饶文碧等[11]提出并行结构损伤动力有限元分析算法,结合 PVM (Parallel Virtual Machine)并行虚拟系统,对比了串行与并行算法的计算效率。林菁淳[12―13]将传统时序分析法与Hadoop平台Map/Reduce编程模型相结合,提出了基于云计算的时序分析方法。陈亮[14]利用MATLAB并行工具箱对ITD模态参数进行了辨识,实现了并行计算程序的单机计算和多机分布式计算。
近年来智能优化算法被用于结构参数识别[15],粒子群优化算法(Particle Swarm Optimizer,PSO)作为一种较为成熟的智能优化算法具有很多优点,但该算法需要进行大量运算,对计算机的配置要求相对较高,计算耗时较长,无法对结构进行实时监测。基于此,本文尝试运用云计算平台,利用分布式并行化的改进思想,对智能优化算法PSCO[16―17]进行改进,研发框架结构物理参数并行识别算法,实现结构响应的快速处理和状态评价,来部分解决上述问题。本文首先搭建了云计算平台,然后对传统MPSCO算法进行了并行化改进,研发了一种基于云计算的框架结构参数并行算法,最后通过 15层框架数值试验和7层钢框架实验室试验的物理参数辨识,验证了算法性能的有效性。
1 基于云计算的结构物理参数并行辨识算法
针对传统MPSCO算法计算效率低、拓展性差等特点,本节首先对云计算平台进行了搭建,接着对MPSCO算法进行并行化改进,然后将改进算法与结构物理参数辨识相结合,提出了基于云计算的结构物理参数并行辨识算法。
1.1 MATLAB云计算平台的搭建
搭建 MATLAB云计算平台,需要用到该软件的并行计算工具箱(Parallel Computing Toolbox,PCT)和分布式计算服务器(MATLAB Distributed Computing Server,MDCS)。前者帮助用户在多核计算机上进行并行计算;后者将单台计算机计算扩展到多台计算机计算,实现分布式集群计算。
MATLAB并行计算分为任务并行(Parfor)和数据并行(Single Program/Multiple Data,SPMD)。并行计算工具箱 PCT提供了一种并行 For循环结构Parfor,在预先设置好 Worker数的前提下,Parfor将各自独立的任务自动分配到不同的Workers进行处理,方便快捷地将传统串行程序转变成并行程序。SPMD虽然在不同的Workers上运行相同代码,但可同时处理多组数据,适用于单机无法存储和计算海量数据等情况,使得计算效率成倍增加。
MDCS分布式计算服务器使MATLAB软件在多台计算机或者服务器上进行分布式集群计算,MDCS能够灵活调度程序作业,在各分布式节点上建立进程,充分利用分布式计算资源进行计算,最后返回各分布式节点的计算结果。
PCT和MDCS结合,完成分布式MATLAB云计算平台的搭建,在接入不同并行核数时可显著提高计算效率。
1.2 并行多粒子群协同优化算法
针对粒子群优化算法的不足,李爱国[18]提出了多粒子群协同优化方法(Particle Swarms Cooperative Optimizer,PSCO),能有效防止粒子陷入局部最优,提高了算法稳定性。董利强[16]提出了一种改进PSCO (MPSCO)算法,本文对MPSCO算法进行了并行改进,提出一种并行多粒子群协同优化(PMPSCO)算法。
1) MPSCO算法
将“多粒子群协同”和“进化理论”的思想相结合,在保证种群多样性的同时,增加了对局部最优粒子的判断处理方法,使得算法的性能得到提高。相较于传统PSO算法,改进算法对PSCO进行了以下改进:
① 将m个子种群分为上下两层,上层子种群中的所有粒子均跟随当前整个种群的最优位置进化,以确保种群有比较快的收敛速度;而下层子种群中的粒子均跟随其所在子种群的最优位置进化,以确保粒子可以比较充分地搜索解空间,以获得更高的求解质量。上层有一个子种群,下层有m-1个子种群,上下两层子种群的速度和位置按式(1)和式(2)更新。

式中:vik和zik分别表示第k次迭代时第i个粒子的速度和位置;pi和pgi分别表示第k次迭代时第i个粒子的最优位置和所在子种群的最优位置;pg表示所有种群的最优位置;k表示当前迭代次数;w为惯性权重因子;c1、c2为学习因子;r1、r2为[0,1]之间的两个随机数。
② 淘汰陷入局部最优子种群中的最差粒子,并用新粒子对其进行替换。首先预先设定好最差粒子标记次数限值Lw,算法运行时,将粒子最差标记次数与限值进行对比,如果等于Lw,则认为该粒子需要替换,故将其替换为当前优良种群的重心位置Zgrav,见式(3),将原粒子替换成新粒子并归零最差标记次数。这种替换方式既能够淘汰局部最优粒子,又能保证新粒子遵循正确的替换方向,向全局最优靠拢。
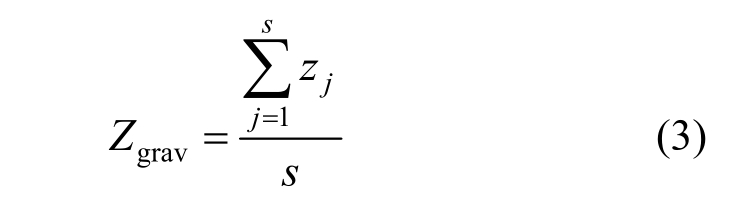
其中,s和zj分别为所设定优良粒子的数量和位置。
2) PMPSCO算法
由于传统算法采用串行计算,计算耗时长、效率低,本节提出了一种 PMPSCO算法,该算法的改进分两步改进:第一步,改进最差粒子替换规则;第二步,对算法进行并行化改进。具体改进如下:
1) 改进最差粒子替换规则
当标记出最差粒子后,首先按照MPSCO算法找到优良粒子重心位置并找到当前最优粒子的位置;通过计算得到优良粒子重心位置和当前最优粒子位置的中点位置记为新的替换粒子;最后用新粒子对最差粒子进行替换。将式(3)替换成式(4),在最差粒子替换过程中,可减少重心粒子适应度较低而替换效率不高的不足,而无需多次计算备选新粒子的适应度值,缩短计算耗时。
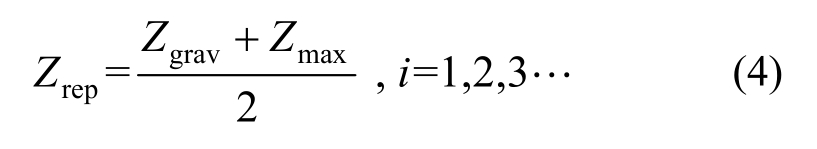
其中:Zrep为选定优良粒子的重心位置和最优良粒子的中点位置;Zmax为最优良粒子的位置。
2) 并行改进
并行化改进可分为两个级别:粒子级别的并行改进和片段计算级别并行改进。
① 粒子级别的并行改进:即粒子迭代更新并行,对每个子种群粒子的速度、位置更新以及适应度函数的计算等步骤进行并行化改进。
PMPSCO算法对粒子级别的并行改进重点改进了计算耗时最多的串行粒子迭代更新过程。该改进利用并行计算工具箱 PCT对传统串行代码进行了修改调整,将不同粒子之间的计算由串行改进成并行过程。传统串行算法更新迭代过程在任何一个粒子更新出错时将无法继续,也不能同时对不同粒子进行更新,而并行迭代过程相互独立,某一粒子更新出错其他粒子仍可以继续更新,且能利用多核技术对不同粒子进行同时处理。
② 片段计算级别并行改进:将完整数据分为多个数据片段或者对同一片段求解多次时所采用的并行改进。
PMPSCO对数据片段级别的并行改进则是通过MATLAB分布式计算服务器MDCS以及单程序多任务SPMD,实现单数据片段多次求解并行和多数据片段多次求解并行。传统算法不同数据片段进行串行计算,在计算完上一片段之后才能计算下一片段,若某一环节出现问题将会导致整个计算过程出错,计算效率低。并行算法针对传统算法不同数据片段之间的计算过程不需要互相交流的特点,利用PCT和SPMD进行并行改进,使得不同数据片段计算从原本只能单核串行计算扩展到能够多核并行计算。
通过以上两种改进,将原本的串行计算过程改进成并行计算过程,利用MATLAB中的PCT工具箱、SPMD和MDCS分布式计算服务器,对PMPSCO算法进行多核、多机分布式集群运算。合理搭建云计算平台,自由选择接入的计算机台数与核数,可随时扩展算法计算效率,以满足SHM系统实时监测的需求。理论上,接入计算的处理器核数和机器台数越多,计算效率越高,当计算量足够大时,计算效率也呈线性增加关系。
1.3 结构参数的并行辨识
为了实现结构物理参数的并行辨识,将PMPSCO算法和结构物理参数识别方法相结合,引入框架结构参数辨识适应度函数。
框架结构参数辨识适应度函数的选择是多样的,不同的适应度函数计算复杂程度和计算精度都不同,因此选择合适的适应度函数对算法的辨识效果至关重要。结合前期研究[17]得出基于动力时程响应(位移、速度或加速度)的适应度函数在框架结构物理参数辨识中具有良好的抗噪性和峰值特性;现有大型结构监测系统收集到的海量数据以变形数据居多,而加速度数据实时性较好,较为可靠,故本文选用基于加速度建立的适应度函数:

其中:Fa为适应度函数;amea(i,j)和anum(i,j)分别表示结构实测与数值模型预测的第i时刻第j测点加速度响应;N为测点总数,在框架结构中测点数等于楼层数;L为测量数据总长度,即每个测点所采集的用于计算的数据个数。
当适应度函数值越大,表示相应粒子所代表的结构物理参数越接近于真实值。此外,对于线性结构预测加速度响应值采用Newmark积分法[19-20]。Newmark积分法是一种给定初始时刻的位移、速度、加速度和整个过程的激励荷载,逐步迭代求得后续时刻的位移、速度、加速度的方法。运用该方法首先需要形成刚度矩阵K、质量矩阵M和阻尼矩阵C,设定初始位移、速度、加速度,以及确定时间步长等参数。
结构参数并行辨识的步骤如下:
① 待辨识结构的物理参数编码:质量已知情况下,需要对结构刚度、阻尼和损伤值进行编码,结构质量未知情况下,需要对结构质量也进行编码,通过编码形成刚度矩阵K、质量矩阵M和阻尼矩阵C;
② 参数设置:包括子种群数量m、子种群大小n、最大迭代次数Imax、学习因子c1、c2、惯性权重W、优良粒子数量s以及最差次数限值Ie等。在选取子种群数量m和子种群大小n时应注意选取的子种群数越多或者子种群大小越大,计算耗时就会成倍增加,选择m=3,n=10,计算精度已经满足要求,再继续增加则精度提升不明显,不利于控制计算耗时。根据前期研究[17],学习因子取c1=c2=2,惯性权重取[0.4,0.9],优良粒子数量s=6,最差次数限值Ie=10;
③ 初始化种群:随机产生m个大小为n的子种群,将种群分为1个上层子种群和m-1个下层子种群,上下两层子种群的速度和位置分别按式(1)和式(2)更新;
④ 分配任务:将子种群迭代任务分配给不同的并行节点;
⑤ 建立适应度函数及计算适应度值:Newmark积分法中初始位移、速度、加速度均设为0,根据式(5)建立适应度函数并计算每个粒子的适应度值;
⑥ 粒子更新与最差粒子替换:按照式(1)、式(2)对粒子进行更新,并根据式(4)对最差粒子进行替换;
⑦ 最优值更新:计算更新后各粒子的适应度值,收集不同计算节点的计算结果,更新最优值;
⑧ 判断是否达到预设最大迭代次数Imax,若未达到则返回步骤⑥,若达到最大迭代次数则停止粒子更新并输出最优值。
2 框架结构数值试验
为验证分布式并行算法对线性结构系统辨识的有效性,以15层剪切型框架结构为例进行分析,并与传统串行算法进行对比。
2.1 结构模型
本数值仿真建立了一个15层剪切型框架模型,分为结构未损伤状态和损伤状态,如图1所示。质量为m1=m2=…=m14=3.78 kg以及m15=3.31 kg,前两阶阻尼比分别为ξ1=ξ2=2%,采用Rayleigh阻尼模型。结构未损伤状态,该结构层间刚度分别为k1=k2=…=k15=375 kN/m;结构损伤状态,设定损伤为第7层刚度下降10%,即k7=337.5 kN/m。在结构顶层施加随机激励F,并采用常规Newmark-β算法计算结构动力响应,采集各层加速度响应。其中,采样频率为1000 Hz,采样时间5 s,对加速度原始数据分别取无噪声和按照式(6)加入信噪比为40 dB、25 dB、20 dB的高斯白噪声。
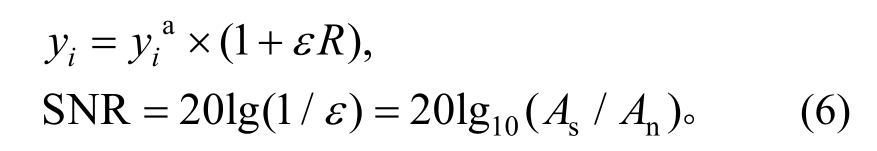
式中:yia和yi分别为原始信号和加入噪声后的信号;ε表示噪声水平;R为标准正态分布随机数;SNR为信噪比;As和An分别为信号和噪声信号的幅值。
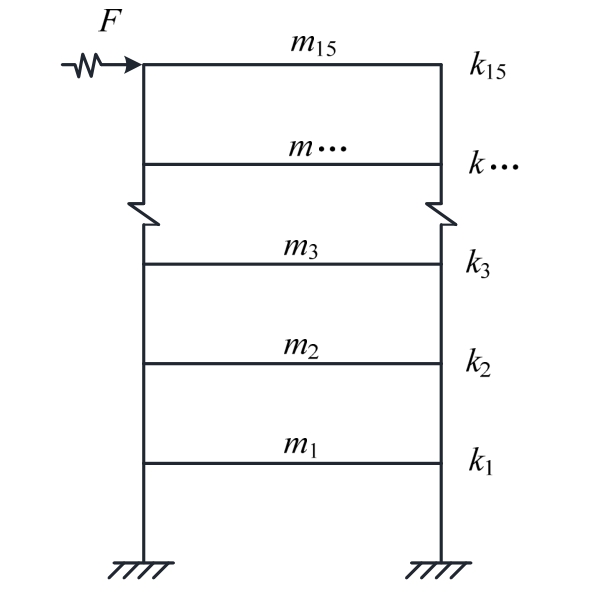
图1 15层框架结构模型示意图
Fig.1 Diagram of 15–story frame model
2.2 并行辨识模型
本文算法运行环境均基于实验室搭建的MATLAB R2016a的分布式云计算平台,该平台采用实验室三台12核心、64 G运行内存的惠普服务器进行搭建,具体配置环境见图2,三台服务器分别为dl380pg801、dl380pg802、dl380pg803,均为在线可用状态。
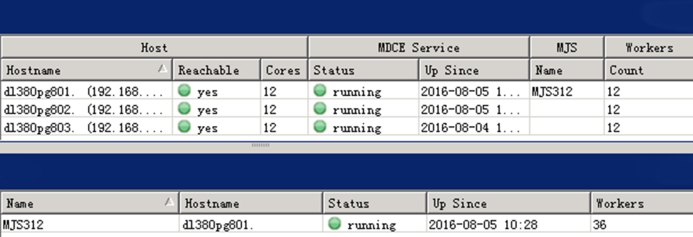
图2 分布式计算管理中心
Fig.2 Management center of distributed computing
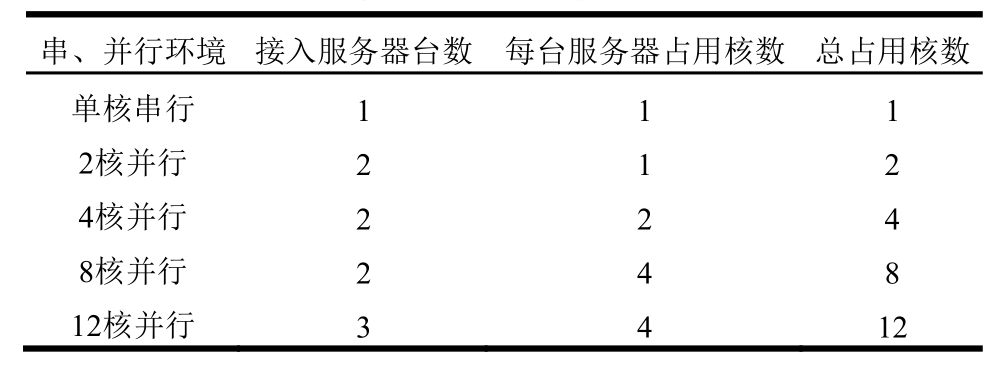
本文运用到的单核串行计算仅利用dl380pg801服务器的单核进行计算,而 2核并行计算是将dl380pg801作为Master服务器,将计算任务分配到不同服务器进行计算。串、并行工况具体配置情况见表1:
辨识模型的建立步骤如下:
① 对待辨识框架结构物理参数进行编码:将结构各层刚度及前两阶阻尼比设为待辨识结构参数,对其进行编码B=[k1,…,k15,ξ1,ξ2],将搜索范围设置为参数理论值的0.1倍~10倍;
表1 串、并行环境配置
Table 1 Setting of serial and parallel environment
② 建立适应度函数:根据前期研究可得,数据长度为500时,其计算效率和精度均保持良好,故提取前 500个加速度响应和激励数据,按式(5)建立适应度函数;
③ 算法参数设置:按1.3节对算法各参数进行设置;
④ 结构物理参数辨识:按 1.3节步骤,分别利用MPSCO与PMPSCO进行单核串行和多机分布式结构物理参数辨识,最大迭代次数取6000次(通过预测试,该算法能在4000次~5500次之间有效收敛);
⑤ 按步骤④计算10组数据,输出10组数据的平均辨识结果,并进行结构健康状况评估。
2.3 辨识结果
基于2.2节建立的并行辨识模型,对15层剪切框架进行结构物理参数辨识,辨识结果及误差见表2、表3。
从表2可以看出结构在健康状态下,随着环境噪声从40 dB增大到25 dB、20 dB,最大识别误差从0.543%增大到0.65%、2.867%,识别值仍与理论值吻合良好;结构损伤状态也存在同样的规律。从表3可以看出结构在第7层发生10%刚度退化时,该算法能准确找到损伤位置(第7层),且识别该层刚度的精度非常高,在20 dB强噪声下的识别误差仅1.158%。可见,本文所提出的方法具有很高的辨识精度和较强的抗噪能力。
2.4 性能比较与讨论
为了比较 PMPSCO方法与传统串行方法的性能,利用串行和并行算法分别对 15层框架结构未损伤状态进行单核串行物理参数辨识,以及2、4、8、12核分布式并行物理参数辨识,串、并行环境配置见表1。分别记录不同算法不同并行情况下的计算耗时以及加速比,这里引入加速比S(n)[13]来反映计算效率:
表2 15层框架未损伤状态参数辨识结果
Table 2 Parameter identification results of undamaged 15-story frame model

其中:误差=|理论值-10组数据平均辨识值|/理论值。
表3 15层框架损伤状态参数辨识结果
Table 3 Parameter identification results of damaged 15-story frame model

其中:n为工况代号;TS(n)为单核串行计算耗时;TP(n)为多核并行计算耗时。
图3比较了单核串行和2、4、8、12核分布式并行物理参数辨识的计算耗时和加速比。可知,单核串行耗时为2832.72 s,而2核分布式并行计算耗时为1628.01 s,2核并行计算耗时仅为单核串行的1/1.74,由式(7)可得2核分布式并行计算加速比为1.74。可以看出,多核分布式并行计算耗时比单核串行计算耗时明显减少,随着核数增加,其加速比呈近似线性增加趋势。当接入12核分布式并行计算时计算耗时为276.01 s,仅为单核串行计算耗时的1/10.26,即加速比为10.26。测试结果中理论加速比与实际加速比有一定差距,实际加速比会稍低于理论加速比,此差距是因为分布式并行计算需要考虑不同节点和不同服务器之间的通信耗时。
3 框架结构试验
本节以一个7层剪切型钢框架结构试验为例进行分析。
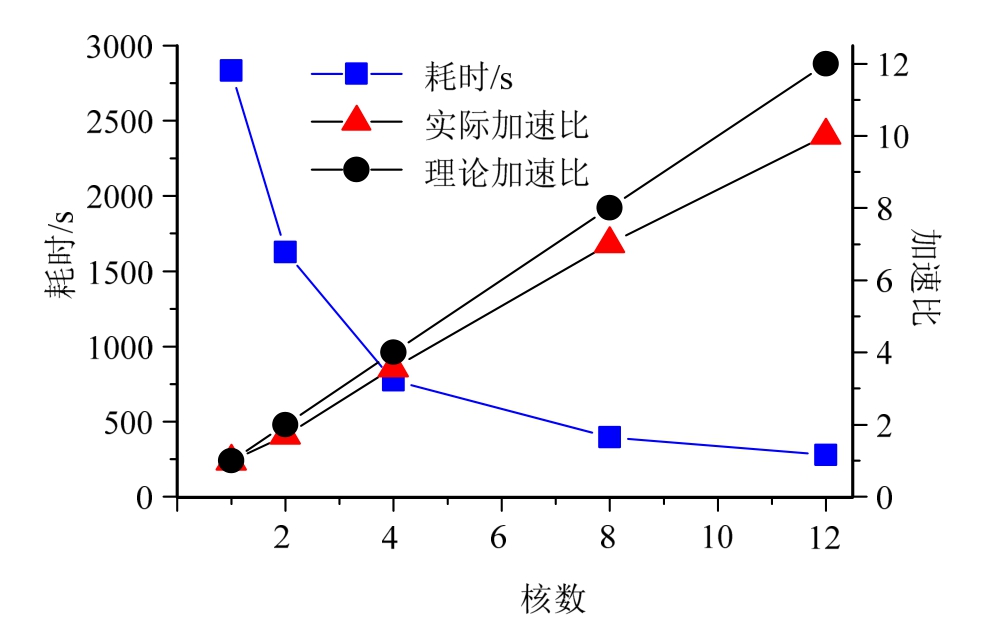
图3 不同算法计算效率比较
Fig.3 Efficiency comparison of different algorithms
3.1 试验模型
为了测试该算法在实际应用中的可行性,本节对实验室条件下的一个 7层钢框架进行了试验研究。结构模型和尺寸如图4所示,结构为一个7层、2×1跨的钢结构框架缩尺模型,柱子是薄钢板,梁是空钢管。模型的平面尺寸为0.4 m×0.2 m,高1.4125 m。框架构件采用热轧300 W级钢材(名义屈服强度为300 MPa),梁、柱截面特性见表4。采用激振器在结构顶层施加随机激励,并利用力传感器和加速度传感器分别记录下激振力的大小和结构各层加速度响应,采样频率为5000 Hz。

图4 结构模型装置图
Fig.4 Setup of structural model
表4 试验模型梁、柱截面特性
Table 4 Properties of beams and columns

该试验分为未损伤、小损伤和大损伤三种工况,小损伤和大损伤工况的损伤位置均设置在第4层中柱,角柱保持不变,试验对每个工况分别测试三次,取得三组数据进行分析。小损伤工况将结构的第四层中间柱子的上下端同时切割出4个7.5 mm长的切口;而大损伤工况将结构的第四层中间柱子的中间完全切断,小损伤、大损伤位置见图 5。每种工况分别取三个片段的前500个加速度及激励数据进行计算,该试验的物理参数辨识步骤与试验配置环境均与2中相同。

图5 大小损伤位置示意图
Fig.5 Location of small and large damage
3.2 辨识模型与辨识结果
对3.1节中7层框架试验模型进行物理参数辨识。平台的搭建和并行辨识算法的建模步骤见 1.2节、1.3节,三个工况辨识结果分别见表5、表6、表7。
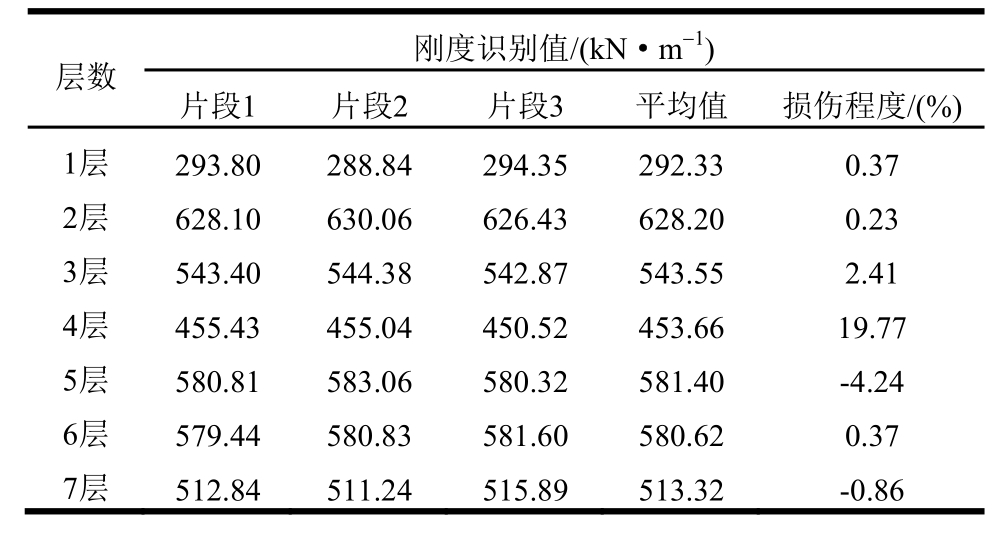
表5辨识结果与文献[16]中未损伤刚度识别值吻合良好,从表5、表6、表7可知,未损伤状态各层刚度识别值均相近,大、小损伤状态也有类似识别结果,证明 PMPSCO算法能够稳定辨识出不同工况状态下的结构层间刚度参数。识别到小损伤状态下第4层的损伤程度为14.00%,大损伤状态下第4层的损伤程度为19.77%;而其他层最大损伤程度为3.37%,第4层的损伤程度明显大于其它层,说明 PMPSCO在小损伤和大损伤工况下,均能准确识别损伤发生位置(第4层)和损伤位置的刚度退化情况,进一步验证了本文所提辨识方法对试验结构物理参数辨识的有效性和稳定性。
表5 未损伤工况参数辨识结果
Table 5 Identification results in undamaged conditions

表6 小损伤工况参数辨识结果
Table 6 Identification results in small damaged conditions
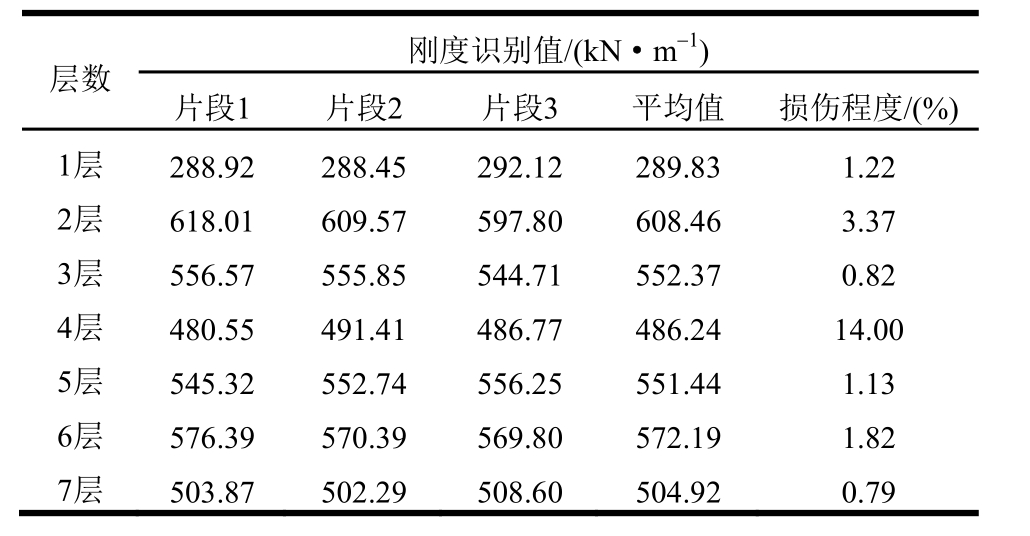
表7 大损伤工况参数辨识结果
Table 7 Identification results in large damaged conditions
3.3 性能比较和讨论
同样地,也对试验模型在分布式并行平台下的计算效率进行了比较,分别对7层试验框架未损伤状态进行单核串行和2、4、8、12核分布式并行物理参数辨识,记录不同算法不同并行情况下的计算耗时情况,过程与2.4节类似。比较结果见图6。
可知,单核串行耗时为2016.73 s,而2核分布式并行计算耗时为1133.03 s,2核并行计算耗时仅为单核串行的1/1.78,2核分布式并行计算加速比为1.78。随着分布式并行核数增加,计算耗时明显减少,其加速比呈近似线性增加趋势。当接入 12核分布式并行计算时计算耗时为209.10 s,仅为单核串行计算耗时的1/9.64,加速比为9.64。该算法对结构试验的辨识加速效率结果与2.4节中相似,进一步验证了该算法在试验模型上的加速效果。
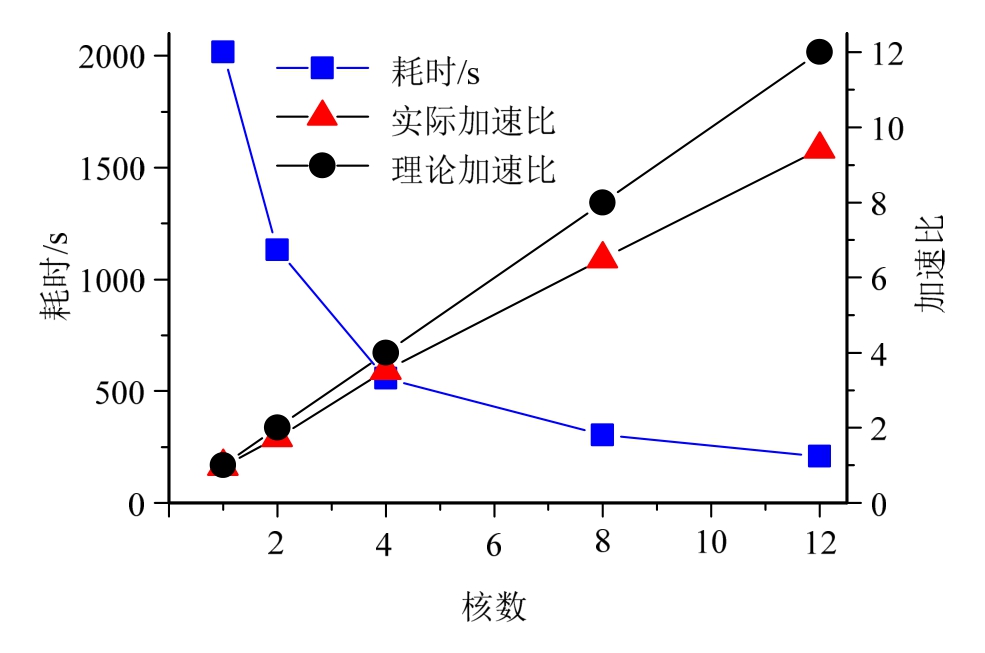
图6 不同计算效率比较
Fig.6 Efficiency comparison of different algorithms
3.4 算法实时性探究
通过图3、图6可以验证该算法在数值模拟试验及实验室模型试验中的加速效果,为了进一步探究在大量计算片段下该算法的加速趋势,分别模拟了100倍、200倍、400倍和800倍数据片段长度情况,这些大量计算片段的并行加速比见表8。
表8 大量计算片段的并行加速比
Table 8 Parallel speedup of large computing fragment
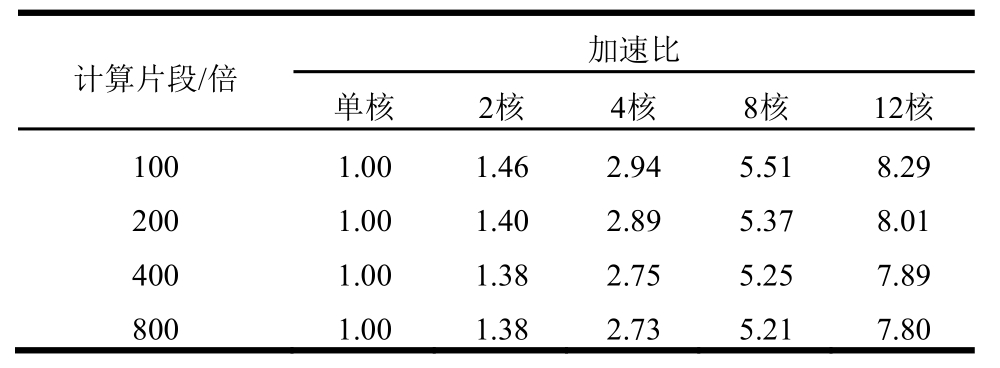
由表8可得,在大量计算片段下,多核分布式并行的加速比虽随着计算片段的增多,加速比稍有下降,但下降幅度不大,其加速效果依然显著。在12核分布式并行环境下,当计算片段增加到800倍时,仍能保持7.80倍的加速效果。
结合云计算的特点,当需要计算大量甚至海量数据时,可通过租用云计算服务器,以提高整个计算系统的计算能力,使得计算不仅仅局限于12核,也不仅仅局限于七八倍的加速效果,为框架结构健康监测提供了实时高精度监测的可能性。
租用云计算服务器的方式比升级单一健康监测系统的硬件更加节约成本和合理利用资源。
4 结论
(1) PMPSCO算法在保持MPSCO算法良好辨识精度的优点下,克服了传统MPSCO算法耗时较长、算法效率拓展能力弱等缺点,数值试验和实验室模型试验均有效验证了这一点;
(2) 提出基于云计算的并行框架结构物理参数辨识方法,数值仿真和试验研究结果均表明该方法的稳定性和辨识精度均较高,抗噪能力强,计算效率拓展能力得到了很大提高,可通过增加云计算平台中分布式并行节点数灵活提高计算效率。
参考文献:
[1]Housner G W, Bergman L A, Caughey T K, et al.Structural control: Past, present, and future [J].Journal of Engineering Mechanics, 1997, 123(9): 897―971.
[2]姜绍飞.结构健康监测导论[M].北京: 科学出版社,2013: 248―305.Jiang Shaofei.Introduction to structural health monitoring[M].Beijing: Science Press, 2013: 248―305.(in Chinese)
[3]陈志为.基于健康监测系统的大跨多荷载桥梁的疲劳可靠度评估[J].工程力学, 2014, 31(7): 99―105.Chen Zhiwei.Fatigue reliability assessment of multi-loading suspension bridges based on SHMs [J].Engineering Mechanics, 2014, 31(7): 99―105.(in Chinese)
[4]林健富, 程瀛, 黄建亮, 等.大型建筑结构健康监测的海量数据处理与数据库开发研究[J].振动与冲击,2010, 29(12): 55―59.Lin Jianfu, Cheng Ying, Huang Jianliang, et al.Massive data processing in large-scale structural health monitoring and the corresponding database development[J].Journal of Vibration and Shock, 2010, 29(12): 55―59.(in Chinese)
[5]李惠, 鲍跃全, 李顺龙, 等.结构健康监测数据科学与工程[J].工程力学, 2015, 32(8): 1―7.Li Hui, Bao Yuequan, Li Shunlong, et al.Data science and engineering for structural health monitoring [J].Engineering Mechanics, 2015, 32(8): 1―7.(in Chinese)
[6]Nikhil S, Vinayak B, Yogesh Z.Virtual machine monitoring in cloud computing [J].Procedia Computer Science, 2016, 79: 135―142.
[7]王金海, 黄传河, 王晶, 等.异构云计算体系结构及其多资源联合公平分配策略[J].计算机研究与发展,2015, 52(6): 1288―1302.Wang Jinhai, Huang Chuanhe, Wang Jing, et al.A heterogeneous cloud computing architecture and multi-resource-joint fairness allocation strategy [J].Journal of Computer Research and Development, 2015,52(6): 1288―1302.(in Chinese)
[8]吉兴全, 王成山.电力系统并行计算方法比较研究[J].电网技术, 2003, 27(4): 22―26.Ji Xingquan, Wang Chengshan.A comparative study on parallel processing applied in power system [J].Power System Technology, 2003, 27(4): 22―26.(in Chinese)
[9]陈占龙, 吴洁, 谢忠, 等.分布式空间信息的对等协同计算机制研究[J].计算机应用研究, 2008, 25(7):2060―2063.Chen Zhanlong, Wu Jie, Xie Zhong, et al.Study of peer-to-peer and cooperating computing of distributed geospatial information [J].Application Research of Computers, 2008, 25(7): 2060―2063.(in Chinese)
[10]潘巍, 李战怀.大数据环境下并行计算模型的研究进展[J].华东师范大学学报(自然科学版), 2014, 2014(5):43―54.Pan Wei, Li Zhanhuai.Development of parallel computing models in the big data era [J].Journal of East China Normal University (Natural Science), 2014,2014(5): 43―54.(in Chinese)
[11]饶文碧, 程洪斌, 吴代华, 等.基于网络并行计算的结构损伤动力有限元分析[J].武汉工业大学学报, 2000,22(5): 108―110.Rao Wenbi, Cheng Hongbin, Wu Daihua, et al.Dynamic finite element analysis of damaged structure using network-based parallel computing [J].Journal of Wuhan University of Technology, 2000, 22(5): 108―110.(in Chinese)
[12]Yu L, Lin J C.Cloud computing-based time series analysis for structural damage detection [J].Journal of Engineering Mechanics, 2017, 143(1): 1―14.
[13]林菁淳.基于云计算的结构损伤检测[D].广州: 暨南大学,2014.Lin Jingchun.Structural damage detection based on cloud computing [D].Guangzhou: Jinan University,2014.(in Chinese)
[14]陈亮.结构健康监测物联网系统的云计算应用研究[D].哈尔滨: 哈尔滨工业大学, 2013.Chen Liang.Study on application of cloud computing in structural health monitoring of things system [D].Harbin: Harbin Institute of Technology, 2013.(in Chinese)
[15]姜绍飞, 吴兆旗.结构健康监测与智能信息处理技术及应用[M].北京: 中国建筑工业出版社,2011: 10―23.Jiang Shaofei, Wu Zhaoqi.Structural health monitoring and intelligent information processing technique and application [M].Beijing: China Architecture and Building Press, 2011: 10―23.(in Chinese)
[16]董利强.基于改进多粒子群协同优化与统计特征提取的智能损伤检测[D].福州: 福州大学, 2012.Dong Liqiang.Intelligent damage detection based on revised multi-particle swarm coevolution optimization and statistical feature extraction [D].Fuzhou: Fuzhou University, 2012.(in Chinese)
[17]吴思瑶.基于改进协同PSO的时变非线性结构损伤识别研究[D].福州: 福州大学, 2014.Wu Siyao.Damage identification for time-varying nonlinear structure based on improved multi-particle swarm coevolution optimization algorithm [D].Fuzhou:Fuzhou University, 2014.(in Chinese)
[18]李爱国.多粒子群协同优化算法[J].复旦学报(自然科学版), 2004, 43(5): 923―925.Li Aiguo.Particle swarms cooperative optimizer [J].Journal of Fudan University (Natural Science), 2004,43(5): 923―925.(in Chinese)
[19]Newmark N M.A method of computation for structural dynamics [J].Proc ASCE, 1959, 85(1): 67―94.
[20]Corporation H P.A time-domain structural damage detection method based on improved multi-particle swarm coevolution optimization algorithm [J].Mathematical Problems in Engineering, 2014, 44(1):77―85.